Webhooks are easy to send. They're hard to deliver reliably
I built a webhook delivery engine from scratch to understand what reliable delivery actually means. Four problems I ran into and how I solved each one.
Webhooks are easy to send. Delivering them is a different story.
I got curious about this while building a side project. My app was sending webhooks, a simple HTTP POST to a client endpoint. It worked. Until it didn't. The endpoint went down briefly, I retried and the client processed the same event twice.
That bug taught me that sending a webhook and delivering it reliably are two different problems. So I built an engine from scratch to understand the difference.
Problem 1: Silent failures
The most basic webhook implementation looks like this:
import requests
requests.post(endpoint_url, json=payload)
That's it. You fire the request and move on. If it succeeds, great. If it fails, you never know.
The endpoint could be down. The network could have dropped the connection. You'd have no idea. The event is just gone.
The fix is straightforward: don't fire and forget. Instead, save the delivery to the database first, then process it asynchronously. If the request fails, you can retry it. If it never gets picked up, it's still in the database.
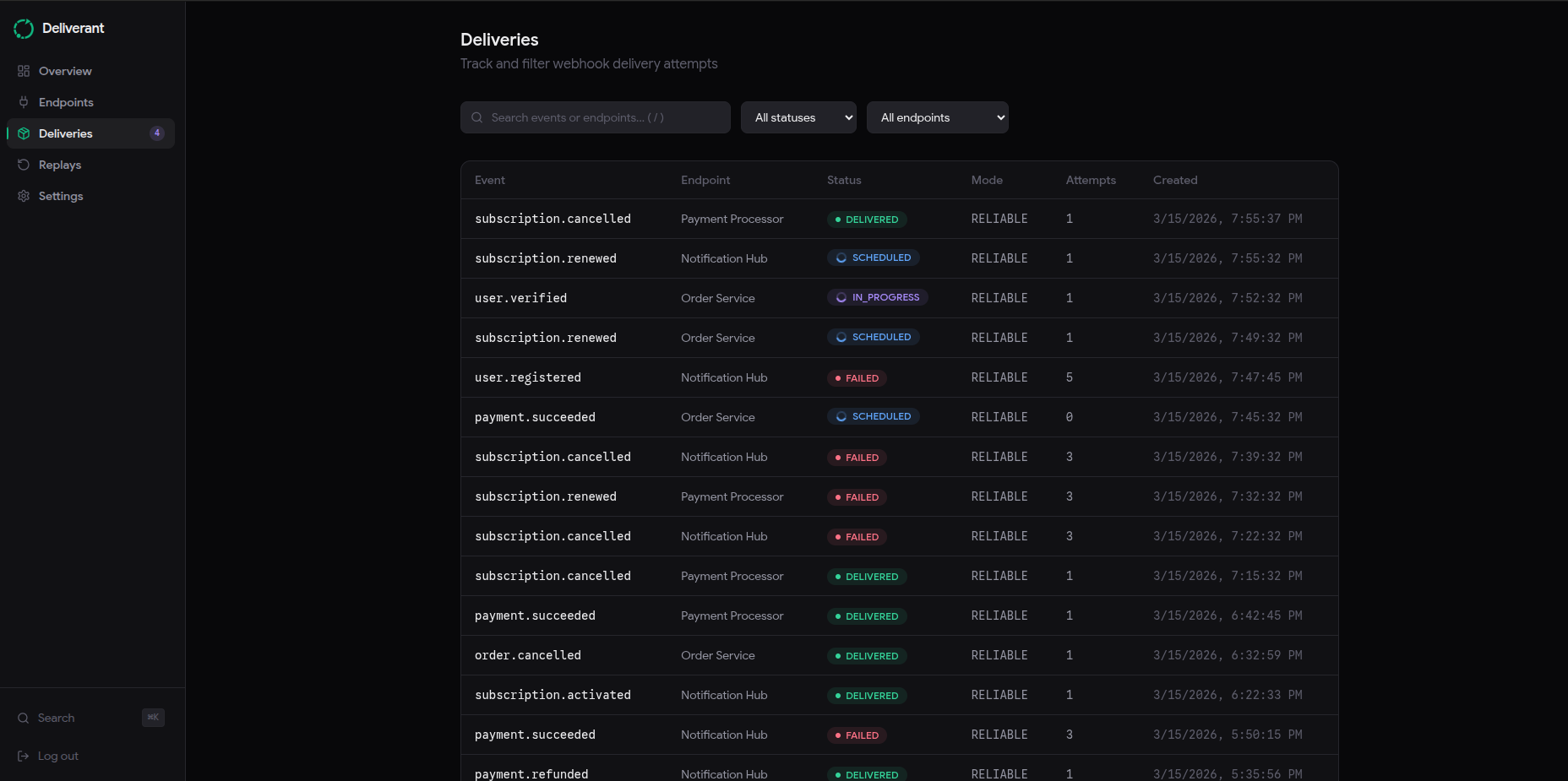
In Deliverant, every event creates a delivery record before anything is sent. The delivery starts in a PENDING state, moves to IN_PROGRESS when a worker picks it up, and only reaches DELIVERED after the endpoint confirms it with a 2xx response. If nothing confirms it, it retries.
Nothing gets silently dropped.
Problem 2: Duplicates
Once you add retries, you get a new problem. If you send a webhook, the endpoint processes it but the response gets lost in transit, you'll retry. Now the endpoint has processed the same event twice.
This is actually harder to solve than silent failures. The obvious answer is to just check if you've seen this event before but that breaks down quickly. What counts as the same event? How long do you keep track? What if the sender sends the same event twice intentionally? Arrghh!
The standard approach is idempotency keys. The sender includes a unique key with each event. If the delivery engine sees the same key again within a defined window, it treats it as a duplicate and skips it. Stripe uses this pattern and I borrowed it for Deliverant.
The window matters. Keep it too short and you miss legitimate retries. Keep it too long and you're storing unnecessary data. I went with 72 hours, which covers any reasonable retry window without being permanent.
POST /v1/events
{
"type": "order.created",
"payload": { "order_id": "ord_abc123" },
"idempotency_key": "create-ord-abc123-1234567890"
}
If Deliverant receives the same idempotency_key twice within 72 hours, the second one comes back with a 200 but no new delivery is created. The sender thinks it worked. No duplicate processing happens on the other end.
Problem 3: Unclear failures
Retries solve availability problems. They don't tell you anything about what actually went wrong.
A delivery can fail for completely different reasons. The endpoint could be down. It could be returning a 400 because your payload schema changed. It could be rate-limiting you with a 429. A network timeout is a different problem from a DNS failure, which is a different problem from a TLS error.
If you retry all of these the same way, you're wasting attempts. A 400 means the endpoint rejected your payload. Retrying it 12 times won't change that.
In Deliverant, every failed attempt gets classified. The worker looks at the outcome and assigns one of these: HTTP_5XX_RETRYABLE, HTTP_4XX_PERMANENT, RATE_LIMITED, TIMEOUT, NETWORK_ERROR, TLS_ERROR, DNS_ERROR.
A 4xx response stops the delivery immediately. There's no point retrying something the endpoint has already told you is wrong. A 5xx or timeout gets scheduled for a retry with exponential backoff, starting at 5 seconds and capping at 24 hours across up to 12 attempts.
You also get the full attempt history in the dashboard. HTTP status, latency, response body snippet and classification for every attempt on every delivery. When something fails, you know exactly what happened and when.
Problem 4: Risky replays
At some point, deliveries will fail and stay failed. Maybe your endpoint was down for hours and exhausted all retry attempts. Now you have a backlog of failed events and you need to re-deliver them.
The naive approach is a retry all button. It kicks off everything at once with no way to preview what will run, no record of who triggered it and no way to stop it once it starts. If something goes wrong, you have no idea what got re-delivered and what didn't.
Deliverant handles replays as a batch operation. You select the failed deliveries you want to re-deliver, optionally run a dry-run first to see what would be created without actually creating anything, then confirm. Every batch gets a record with a status, a count of created deliveries, and a reference back to the source deliveries.
POST /v1/batches
{
"delivery_ids": ["del_abc123", "del_def456"],
"dry_run": true
}
The dry run returns exactly what would happen. Once you're satisfied, you run it for real. The audit trail stays whether it was a dry run or not.
That's the difference between retry all and hope and actually knowing what you did.
The architecture
The stack is Django, Celery, Redis and PostgreSQL. Nothing exotic.
Django handles the API. Every ingest request, delivery query and replay operation goes through it. I chose Django because I know it well and because the ORM makes it easy to enforce the kind of invariants this system needs: unique constraints on idempotency keys, atomic state transitions, that sort of thing.
PostgreSQL is the source of truth. Every event, delivery and attempt lives there. If anything crashes, the database has the full history and the system can recover from it.
Celery runs the delivery workers and the retry scheduler. The scheduler runs on a beat timer and queries for deliveries that are due for their next attempt. Workers pick them up, execute the HTTP request, record the outcome and either mark the delivery as done or schedule the next retry.
Redis is the task queue for Celery and also handles one other thing: the kill switch. There's a Redis-backed flag that pauses all delivery processing instantly without a deployment. Useful when something is wrong and you need to stop the workers immediately.
The dashboard is Next.js. It talks to Django through a BFF layer. Next.js API routes proxy requests to the backend, with the API key stored in an HttpOnly cookie rather than exposed to the browser.
The whole thing runs with docker compose up --build. API, workers, scheduler, dashboard, Postgres, Redis. All of it.
What's next
Deliverant is open source and self-hostable today. If you want to run it yourself:
git clone https://github.com/aayodejii/deliverant.git
cd deliverant
docker compose up --build
The API starts at http://localhost:8000, the dashboard at http://localhost:3000. The full API reference is at deliverant.co/docs.
A hosted version is coming. If you'd rather not manage the infrastructure yourself, join the waitlist at deliverant.co and I'll let you know when it's ready.
If you have questions or want to contribute, the repo is at github.com/aayodejii/deliverant.